Breaking the Monolith: Modular Multi-Tiered Load Balancing in Serverless Computing
How I redesigned the AutoNDP architecture to support modular, policy-driven load balancing—achieving greater scalability and flexibility in serverless computing.
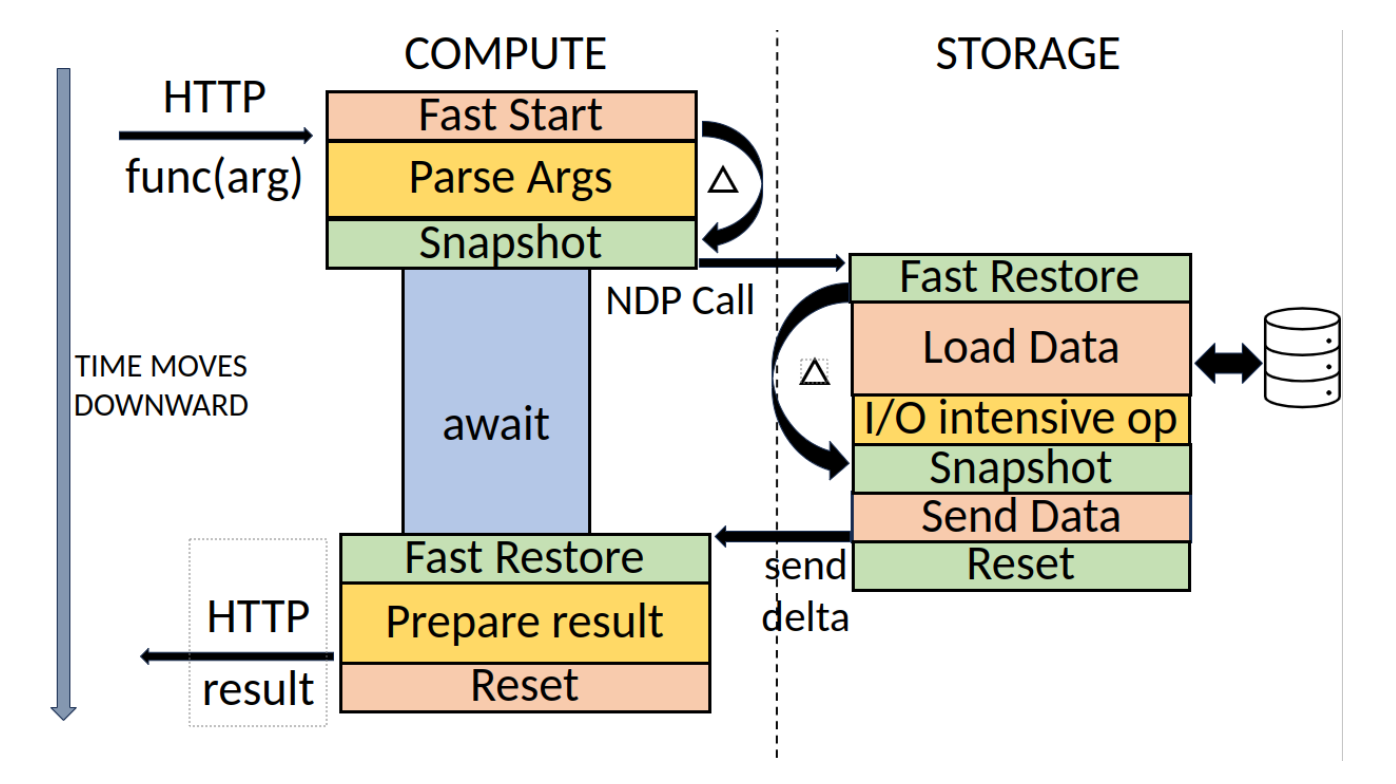
In the evolving landscape of cloud computing, serverless architectures promise effortless scalability and reduced operational overhead. But beneath the abstraction lies a real challenge: efficiently distributing work across a heterogeneous, distributed runtime without creating bottlenecks or single points of failure.
In my final-year dissertation—later incorporated into the SoCC'24 paper on dynamic multi-tiered load balancing—I tackled this challenge by redesigning the load balancing system for AutoNDP, a funclet-migration runtime built on Faasm.
The Problem
The original AutoNDP runtime relied on:
- A single compute node as the entry point for all invocations.
- Static round-robin balancing between compute nodes.
- Minimal configurability and no real adaptation to workload changes.
This design created clear scaling limits:
- One node acted as a bottleneck and single point of failure.
- The scheduler only redistributed work after a node hit capacity.
- No flexibility for cloud providers to tune or replace policies.
My Contribution: Multi-Tiered, Modular Load Balancing
I implemented a three-layer balancing framework designed around three principles: Configurability, Modularity, and Scalability.
1. Invocation Layer Distribution
At the system's entry point, I introduced a configurable dispatcher:
- Replaced the single-node invoker with a round-robin dispatcher across all compute nodes.
- Supported pluggable policies—administrators can select or implement their own by conforming to an
ILoadBalancerStrategyinterface. - State persisted across invocations using Redis, enabling distribution decisions without losing context.
2. Inter-Node Balancing
I refactored Faasm’s tightly coupled scheduler into a policy-driven engine:
- Decoupled scheduling logic from core runtime to support modular policies like
MostSlotsandLeastLoad. - Integrated a metrics collection module to provide live CPU, RAM, and load average data from each node via
/proc. - Allowed policies to make real-time, informed balancing decisions.
3. Storage Layer Data Distribution
At the Ceph storage layer:
- Increased placement groups from 1 → 128 for better parallelism.
- Enabled autoscaling and rebalanced data to prevent hot-spotting.
- Extended offloading decisions beyond simple thread availability to include CPU, memory, and load thresholds—fully configurable per deployment.
Why Modularity Matters
By designing the balancer as a set of interchangeable components, AutoNDP now:
- Supports deployment-specific tuning without modifying core code.
- Allows experimentation with new strategies (including future ML-based policies).
- Can scale horizontally without major re-architecture.
Results
Benchmarks showed:
- 3.13× lower median latency for I/O-intensive workloads.
- 10× reduction in latency variance under high concurrency.
- More stable throughput with reduced queuing effects.
While some end-to-end workloads showed the storage offloading bottlenecks still need attention, the architectural flexibility I introduced positions the system for future scaling without major rewrites.
Looking Ahead
The multi-tiered load balancer opens the door to:
- Adaptive policies that evolve with workload patterns.
- Integration with predictive schedulers and demand forecasting.
- Applying the modular approach to other runtime services in distributed FaaS systems.
This work was not just an exercise in squeezing out performance—it was a case study in engineering for flexibility, ensuring that when workloads, hardware, or requirements change, the system can adapt without tearing apart its foundation.